import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import ipywidgets as widgets
import numpy as np
import calendar
from datetime import datetime, timedelta
import os
from babel.numbers import format_currency
from ipywidgets import interactThe CAMT.053 file format is a standard XML format for exporting transactions and account balances to, for example, an accounting package. Most (European) banks allow their customers to download their transactions and balances in this file format from their banking portal. In this post I’ll show how to read CAMT.053 files into Pandas dataframes.
I wrote this code because I wanted to get a better grip on how I’m spending my hard-earned money. Besides showing how to read CAMT.053 files into dataframes, I’ll also demonstrate how to categorize transactions and display some pretty graphs using Matplotlib.
About the CAMT.053 file format
Schematically, a CAMT.053 file has the following structure:
- Group Header
- Statements
- Balances
- Entries
- Entry Details
Each file starts with a group header followed by one or more statements. Each statement may contain multiple account balances and multiple transactions (entries). Each entry (transaction) can contain one or more entry details.
Pandas can read XML files using the read_xml() function. However, because of how deeply nested CAMT.053 files are, we need to first flatten its structure using XSLT stylesheets.
I created a set of stylesheets for flattening group headers, balances, statements and entries. Using these, we’ll be able to read each of these into a separate dataframe.
File: groupheader.xsl
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:camt="urn:iso:std:iso:20022:tech:xsd:camt.053.001.02">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="/camt:Document/camt:BkToCstmrStmt/camt:GrpHdr">
<data>
<row>
<MessageIdentification><xsl:value-of select="camt:MsgId"/></MessageIdentification>
<CreationDateTime><xsl:value-of select="camt:CreDtTm"/></CreationDateTime>
<xsl:if test="camt:MsgPgntn">
<PageNumber><xsl:value-of select="camt:MsgPgntn/camt:PgNb"/></PageNumber>
<LastPageIndicator><xsl:value-of select="camt:MsgPgntn/camt:LastPgInd"/></LastPageIndicator>
</xsl:if>
</row>
</data>
</xsl:template>
</xsl:stylesheet>File: balance.xsl
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:camt="urn:iso:std:iso:20022:tech:xsd:camt.053.001.02">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="/camt:Document/camt:BkToCstmrStmt">
<data>
<xsl:for-each select="camt:Stmt/camt:Bal">
<row>
<Identification><xsl:value-of select="../camt:Id"/></Identification>
<xsl:if test="camt:Tp/camt:CdOrPrtry/camt:Cd">
<Code><xsl:value-of select="camt:Tp/camt:CdOrPrtry/camt:Cd"/></Code>
</xsl:if>
<xsl:if test="camt:Tp/camt:CdOrPrtry/camt:Prtry">
<Proprietary><xsl:value-of select="camt:Tp/camt:CdOrPrtry/camt:Prtry"/></Proprietary>
</xsl:if>
<Amount><xsl:value-of select="camt:Amt"/></Amount>
<Currency><xsl:value-of select="camt:Amt/@Ccy"/></Currency>
<CreditDebitIndicator><xsl:value-of select="camt:CdtDbtInd"/></CreditDebitIndicator>
<Date><xsl:value-of select="camt:Dt"/></Date>
</row>
</xsl:for-each>
</data>
</xsl:template>
</xsl:stylesheet>File: statement.xsl
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:camt="urn:iso:std:iso:20022:tech:xsd:camt.053.001.02">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="/camt:Document/camt:BkToCstmrStmt">
<data>
<row>
<xsl:for-each select="camt:Stmt">
<MessageIdentification><xsl:value-of select="/camt:Document/camt:BkToCstmrStmt/camt:GrpHdr/camt:MsgId"/></MessageIdentification>
<Identification><xsl:value-of select="camt:Id"/></Identification>
<xsl:if test="camt:ElctrncSeqNb">
<ElectronicSequenceNumber><xsl:value-of select="camt:ElctrncSeqNb"/></ElectronicSequenceNumber>
</xsl:if>
<CreationDateTime><xsl:value-of select="camt:CreDtTm"/></CreationDateTime>
<IBAN><xsl:value-of select="camt:Acct/camt:Id/camt:IBAN"/></IBAN>
<xsl:if test="camt:Acct/camt:Ccy">
<Currency><xsl:value-of select="camt:Acct/camt:Ccy"/></Currency>
</xsl:if>
<xsl:if test="camt:Acct/camt:Svcr">
<BIC><xsl:value-of select="camt:Acct/camt:Svcr/camt:FinInstnId/camt:BIC"/></BIC>
</xsl:if>
</xsl:for-each>
</row>
</data>
</xsl:template>
</xsl:stylesheet>File: entry.xsl
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:camt="urn:iso:std:iso:20022:tech:xsd:camt.053.001.02">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="/camt:Document/camt:BkToCstmrStmt">
<data>
<xsl:for-each select="camt:Stmt/camt:Ntry">
<row>
<Identification><xsl:value-of select="../camt:Id"/></Identification>
<Amount><xsl:value-of select="camt:Amt"/></Amount>
<Currency><xsl:value-of select="camt:Amt/@Ccy"/></Currency>
<CreditDebitIndicator><xsl:value-of select="camt:CdtDbtInd"/></CreditDebitIndicator>
<Status><xsl:value-of select="camt:Sts"/></Status>
<xsl:if test="camt:BookgDt">
<BookingDate><xsl:value-of select="camt:BookgDt/camt:Dt"/></BookingDate>
</xsl:if>
<xsl:if test="camt:ValDt">
<ValueDate><xsl:value-of select="camt:ValDt/camt:Dt"/></ValueDate>
</xsl:if>
<xsl:if test="camt:AcctSvcrRef">
<AccountServicerReference><xsl:value-of select="camt:AcctSvcrRef"/></AccountServicerReference>
</xsl:if>
<xsl:if test="camt:BkTxCd/camt:Domn">
<DomainCode><xsl:value-of select="camt:BkTxCd/camt:Domn/camt:Cd"/></DomainCode>
<FamilyCode><xsl:value-of select="camt:BkTxCd/camt:Domn/camt:Fmly/camt:Cd"/></FamilyCode>
<SubFamilyCode><xsl:value-of select="camt:BkTxCd/camt:Domn/camt:Fmly/camt:SubFmlyCd"/></SubFamilyCode>
</xsl:if>
<xsl:if test="camt:BkTxCd/camt:Prtry">
<ProprietaryCode><xsl:value-of select="camt:BkTxCd/camt:Prtry/camt:Cd"/></ProprietaryCode>
<xsl:if test="camt:BkTxCd/camt:Prtry/camt:Issr">
<Issuer><xsl:value-of select="camt:BkTxCd/camt:Prtry/camt:Issr"/></Issuer>
</xsl:if>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:MsgId">
<DetailsMessageIdentification><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:MsgId"/></DetailsMessageIdentification>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:InstrId">
<DetailsInstructionIdentification><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:InstrId"/></DetailsInstructionIdentification>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:AcctSvcrRef">
<DetailsAccountServicerReference><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:AcctSvcrRef"/></DetailsAccountServicerReference>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:EndToEndId">
<DetailsEndToEndIdentification><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:EndToEndId"/></DetailsEndToEndIdentification>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:MndtId">
<DetailsMandateIdentification><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:MndtId"/></DetailsMandateIdentification>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:TxId">
<DetailsTransactionIdentification><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:Refs/camt:TxId"/></DetailsTransactionIdentification>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:AmtDtls/camt:TxAmt/camt:Amt">
<DetailsAmount><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:AmtDtls/camt:TxAmt/camt:Amt"/></DetailsAmount>
<DetailsCurrency><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:AmtDtls/camt:TxAmt/camt:Amt/@Ccy"/></DetailsCurrency>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Cdtr/camt:Nm">
<DetailsCreditorName><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Cdtr/camt:Nm"/></DetailsCreditorName>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Cdtr/camt:PstlAdr/camt:Ctry">
<DetailsCreditorCountry><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Cdtr/camt:PstlAdr/camt:Ctry"/></DetailsCreditorCountry>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Dbtr/camt:Nm">
<DetailsDebtorName><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:Dbtr/camt:Nm"/></DetailsDebtorName>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:CdtrAcct/camt:Id/camt:IBAN">
<DetailsCreditorIBAN><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:CdtrAcct/camt:Id/camt:IBAN"/></DetailsCreditorIBAN>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:DbtrAcct/camt:Id/camt:IBAN">
<DetailsDebtorIBAN><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdPties/camt:DbAcct/camt:Id/camt:IBAN"/></DetailsDebtorIBAN>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:DbtrAgt/camt:FinInstnId/camt:BIC">
<DetailsDebtorAgentBIC><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:DbtrAgt/camt:FinInstnId/camt:BIC"/></DetailsDebtorAgentBIC>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:CdtrAgt/camt:FinInstnId/camt:BIC">
<DetailsCreditorAgentBIC><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:CdtrAgt/camt:FinInstnId/camt:BIC"/></DetailsCreditorAgentBIC>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:DbtrAgt/camt:FinInstnId/camt:BIC">
<DetailsDebtorAgentBIC><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RltdAgts/camt:DbtrAgt/camt:FinInstnId/camt:BIC"/></DetailsDebtorAgentBIC>
</xsl:if>
<xsl:if test="camt:NtryDtls/camt:TxDtls/camt:RmtInf/camt:Ustrd">
<DetailsRemittanceInformationUnstructured><xsl:value-of select="camt:NtryDtls/camt:TxDtls/camt:RmtInf/camt:Ustrd"/></DetailsRemittanceInformationUnstructured>
</xsl:if>
<xsl:if test="camt:AddtlNtryInf">
<AdditionalEntryInformation><xsl:value-of select="camt:AddtlNtryInf"/></AdditionalEntryInformation>
</xsl:if>
</row>
</xsl:for-each>
</data>
</xsl:template>
</xsl:stylesheet>Many of the values in the CAMT.053 files are optional and it depends on your bank whether or not certain fields are provided. I tested the stylesheets on the XML files provided by the banks I have accounts with. It might be that your bank provides additional values that you’re interested in. In that case you’ll have to extend one or more of the stylesheets.
See this document for all the nitty-gritty details on the CAMT.053 format and its structure.
Importing dependencies
We start by importing the necessary dependencies.
Reading CAMT.053 files
The following constant defines where we will read the CAMT.053 files from.
IMPORT_PATH = "import"Make sure that you place all CAMT.053 files you download from your banking portal into this directory.
Now we’re ready to import all files in the import directory into a set of dataframes. Note how we provide the stylesheets as an argument to the read_xml call.
groupheaders = pd.DataFrame()
statements = pd.DataFrame()
balances = pd.DataFrame()
entries = pd.DataFrame()
for file in os.listdir(IMPORT_PATH):
# groupheaders
df = pd.read_xml(os.path.join(IMPORT_PATH, file), stylesheet="groupheader.xsl")
df.insert(0, "FileName", file)
groupheaders = pd.concat([groupheaders, df], ignore_index=True)
# statements
df = pd.read_xml(os.path.join(IMPORT_PATH, file), stylesheet="statement.xsl")
df.insert(0, "FileName", file)
statements = pd.concat([statements, df], ignore_index=True)
# balances
df = pd.read_xml(os.path.join(IMPORT_PATH, file), stylesheet="balance.xsl")
df.insert(0, "FileName", file)
balances = pd.concat([balances, df], ignore_index=True)
df = pd.read_xml(os.path.join(IMPORT_PATH, file), stylesheet="entry.xsl")
df.insert(0, "FileName", file)
entries = pd.concat([entries, df], ignore_index=True)
groupheaders['CreationDateTime'] = pd.to_datetime(groupheaders.CreationDateTime)
groupheaders.sort_values('CreationDateTime', ignore_index=True, inplace=True)
statements['CreationDateTime'] = pd.to_datetime(statements.CreationDateTime)
statements.sort_values('CreationDateTime', ignore_index=True, inplace=True)
balances['Date'] = pd.to_datetime(balances.Date)
balances.sort_values('Date', ignore_index=True, inplace=True)
entries['BookingDate'] = pd.to_datetime(entries.BookingDate)
entries['ValueDate'] = pd.to_datetime(entries.ValueDate)
entries.sort_values('BookingDate', ignore_index=True, inplace=True)The groupheaders dataframe has the following structure:
groupheaders.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 707 entries, 0 to 706
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FileName 707 non-null object
1 MessageIdentification 707 non-null object
2 CreationDateTime 707 non-null object
3 PageNumber 705 non-null float64
4 LastPageIndicator 705 non-null object
dtypes: float64(1), object(4)
memory usage: 27.7+ KBThe statements dataframe looks like this:
statements.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 707 entries, 0 to 706
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FileName 707 non-null object
1 MessageIdentification 707 non-null object
2 Identification 707 non-null object
3 ElectronicSequenceNumber 707 non-null int64
4 CreationDateTime 707 non-null object
5 IBAN 707 non-null object
6 Currency 707 non-null object
7 BIC 707 non-null object
dtypes: int64(1), object(7)
memory usage: 44.3+ KBThe account balances can be found in the balances dataframe.
balances.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1426 entries, 0 to 1425
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FileName 1426 non-null object
1 Identification 1426 non-null object
2 Code 1426 non-null object
3 Amount 1426 non-null float64
4 Currency 1426 non-null object
5 CreditDebitIndicator 1426 non-null object
6 Date 1426 non-null datetime64[ns]
dtypes: datetime64[ns](1), float64(1), object(5)
memory usage: 78.1+ KBThe entries dataframe has the most columns and contains each transaction.
entries.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2308 entries, 0 to 2307
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 FileName 2308 non-null object
1 Identification 2308 non-null object
2 Amount 2308 non-null float64
3 Currency 2308 non-null object
4 CreditDebitIndicator 2308 non-null object
5 Status 2308 non-null object
6 BookingDate 2308 non-null datetime64[ns]
7 ValueDate 2308 non-null datetime64[ns]
8 AccountServicerReference 1319 non-null object
9 DomainCode 2203 non-null object
10 FamilyCode 2203 non-null object
11 SubFamilyCode 2203 non-null object
12 ProprietaryCode 2308 non-null object
13 Issuer 2308 non-null object
14 AdditionalEntryInformation 2203 non-null object
15 DetailsAccountServicerReference 603 non-null object
16 DetailsEndToEndIdentification 677 non-null object
17 DetailsAmount 603 non-null float64
18 DetailsCurrency 603 non-null object
19 DetailsCreditorName 512 non-null object
20 DetailsCreditorIBAN 512 non-null object
21 DetailsDebtorAgentBIC 636 non-null object
22 DetailsCreditorAgentBIC 644 non-null object
23 DetailsRemittanceInformationUnstructured 703 non-null object
24 DetailsMessageIdentification 393 non-null object
25 DetailsDebtorName 165 non-null object
26 DetailsDebtorIBAN 0 non-null float64
27 DetailsMandateIdentification 357 non-null object
28 DetailsCreditorCountry 254 non-null object
29 DetailsInstructionIdentification 74 non-null object
30 DetailsTransactionIdentification 74 non-null object
dtypes: datetime64[ns](2), float64(3), object(26)
memory usage: 559.1+ KBYour dataframe may contain less columns if your bank doesn’t provide that specific data in its CAMT.053 files.
Creating some useful plots
Now let’s see how we can use this data to create some nice looking graphs.
Account balance over time
By joining the balances and statements dataframes we can plot the account balance over time. A dropdown widget is used to select the account number. For each month, we’ll plot the mean balance. For obvious reasons I’m showing ficticious data.
@interact(iban=widgets.Dropdown(options=statements.IBAN.unique(), description='Account:'))
def plot_account_balance(iban):
statement_balances = pd.merge(left=balances, right=statements, left_on=['FileName','Identification'], right_on=['FileName','Identification']).query('Code=="CLBD" & IBAN==@iban')
statement_balances.loc[statement_balances['CreditDebitIndicator'] == 'DBIT', 'Amount'] *= -1
xticks = [(y, m) for y, m in statement_balances.groupby([statement_balances.Date.dt.year, statement_balances.Date.dt.month]).size().index]
xtick_labels = ["{}, {}".format(y, m) for y, _, m in statement_balances.groupby([statement_balances.Date.dt.year, statement_balances.Date.dt.month, statement_balances.Date.dt.month_name()]).size().index]
ax = (statement_balances
.groupby([statement_balances.Date.dt.year, statement_balances.Date.dt.month])['Amount'].mean()
.plot(kind='line', figsize=(14,5))
)
ax.set_xticks(np.arange(0,len(xticks),1))
ax.set_xticklabels(xtick_labels, rotation = 90)
ax.set_xlabel(None)
ax.yaxis.set_major_formatter(ticker.FormatStrFormatter("\u20ac%d"))
plt.plot()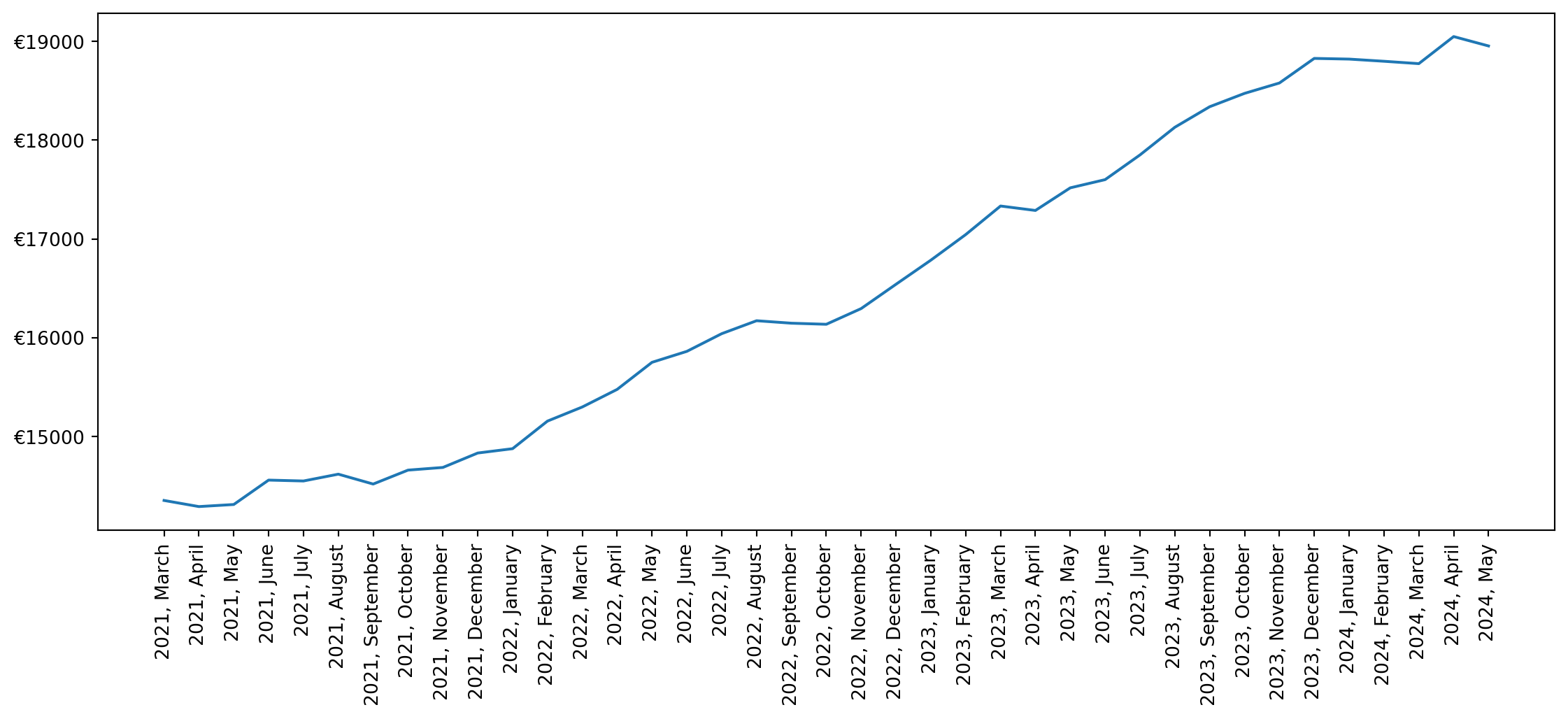
Income vs. expenses over time
To get an idea of one’s monthly income and expenses over time we can plot a grouped bar chart. We’ll use a dropdown widget to select the account number and a slider to select the date range.
dates = pd.date_range(entries.ValueDate.min(), entries.ValueDate.max() + timedelta(days=31), freq='M')@interact(
iban=widgets.Dropdown(options=statements.IBAN.unique(), description='Account:', layout={'width': '500px'}),
date_range=widgets.SelectionRangeSlider(
options=[(date.strftime(' %b %Y '), date) for date in dates],
index=(0, len(dates)-1),
description='Dates:',
layout={'width': '500px'}
)
)
def plot_income_expenses(iban, date_range):
start_date = datetime(date_range[0].year, date_range[0].month, 1)
end_date = date_range[1]
transactions = pd.merge(left=statements, right=entries, left_on=['FileName', 'Identification'], right_on=['FileName', 'Identification']).query('IBAN == @iban & ValueDate >= @start_date & ValueDate <= @end_date')
xticks = ["{}, {}".format(y, m) for y, _, m in transactions.groupby([transactions.ValueDate.dt.year, transactions.ValueDate.dt.month, transactions.ValueDate.dt.month_name()]).size().index]
ax = (transactions
.groupby([transactions.ValueDate.dt.year, transactions.ValueDate.dt.month, 'CreditDebitIndicator'])['Amount'].sum().unstack('CreditDebitIndicator')
.plot(kind='bar', figsize=(14,5), color=['tab:blue', 'tab:orange'])
)
ax.legend(['Income', 'Expenses'])
ax.set_xticklabels(xticks)
ax.set_xlabel(None)
ax.yaxis.set_major_formatter(ticker.FormatStrFormatter("\u20ac%d"))
# Calculate average values
averages = transactions.groupby([transactions.ValueDate.dt.year, transactions.ValueDate.dt.month, 'CreditDebitIndicator'])['Amount'].sum().unstack('CreditDebitIndicator').mean()
# Plot average lines
ax.axhline(y=averages.get('CRDT', 0), linestyle='--', color='tab:blue')
ax.axhline(y=averages.get('DBIT', 0), linestyle='--', color='tab:orange')
plt.plot()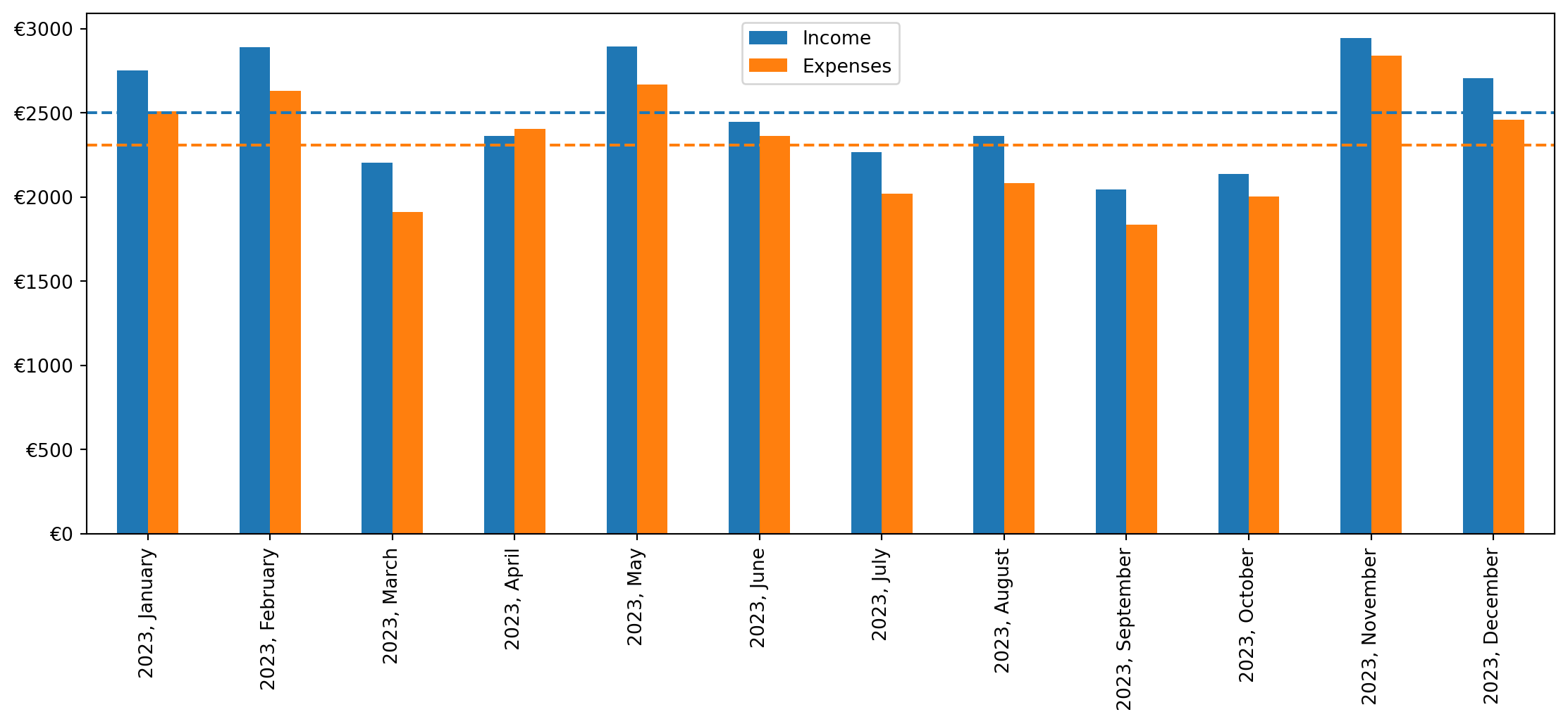
The two horizontal lines show the average income and expenses in the selected date range.
Heatmap of income and expenses
We can subtract the expenses from the income for each month and turn this into a heatmap. This shows the monthly increase or decrease of money in an account.
@interact(iban=widgets.Dropdown(options=statements.IBAN.unique(), description='Account:'))
def plot_heatmap_income_expenses(iban):
transactions = pd.merge(left=statements, right=entries, left_on=['FileName', 'Identification'], right_on=['FileName', 'Identification']).query('IBAN == @iban')
transactions.loc[transactions['CreditDebitIndicator'] == 'DBIT', 'Amount'] *= -1
df = (transactions.groupby([transactions.ValueDate.dt.year, transactions.ValueDate.dt.month])['Amount'].sum().unstack(1)
.rename_axis('Year').rename_axis('Month', axis='columns')
.reindex(list(range(1,13)), axis='columns', fill_value=0)
.rename(columns=lambda x: list(calendar.month_name)[x]))
v = max(df.max(axis=None), df.min(axis=None))
display(df
.style.format(na_rep=0, precision=2).background_gradient(cmap='RdBu', vmin=-v, vmax=v)
.applymap(lambda x: 'background-color: white; color: white;' if pd.isnull(x) or x==0 else '')
)| Month | January | February | March | April | May | June | July | August | September | October | November | December |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||||
| 2021 | 0 | 0 | 50.12 | -61.77 | 21.83 | 247.10 | -8.50 | 69.29 | -99.98 | 141.42 | 27.40 | 146.08 |
| 2022 | 44.12 | 279.10 | 143.02 | 178.19 | 274.45 | 111.13 | 179.65 | 131.15 | -24.88 | -10.51 | 159.53 | 246.07 |
| 2023 | 244.03 | 259.47 | 289.19 | -44.69 | 229.24 | 83.17 | 250.44 | 280.18 | 208.55 | 135.56 | 105.18 | 249.79 |
| 2024 | -6.29 | -21.15 | -23.76 | 274.46 | -95.00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
A blue positive number means we spent less than we earned. A red negative number means we spent more than we earned. A negative number doesn’t mean we are in debt. Similarly, a positive blue number doesn’t mean that we have money in our account. The numbers and colors only indicate whether our account balance has increased or decreased and by how much.
Categorizing transactions
By categorizing bank transactions we can get a better sense of where our money is going. I tried to automatically categorize transactions using an LLM and also experimented with active learning. In the end I concluded that matching keywords in transaction descriptions actually worked best. For example, transactions with “Starbucks” or “Lidl” can be tagged as food, while those with “Uber” or “Lyft” would be categorized under transportation.
We start out with a dataframe of uncategorized transactions.
transactions = pd.merge(left=statements, right=entries, left_on=['FileName', 'Identification'], right_on=['FileName', 'Identification'])Coming up with a good list of categories was challenging. In the end I settled on the categories suggested here.
categories = {
"Income": ["Salary", ...],
"Giving": ["Gift", "WWF", ...],
"Saving": ["Savings", "Retirement", ...],
"Food": ["Albert Heijn", "Jumbo", "Lidl", "Starbucks", "Restaurant", ...],
"Utilities": ["Vitens", "KPN", "Vattenfall", "Internet Services", ...],
"Housing": ["Mortage", ...],
"Transportation": ["NS", "OV-Chipkaart", "Uber", "Lyft", ...],
"Health": ["Infomedics", ...],
"Insurance": ["AEGON", "Centraal beheer", ...],
"Trips and Entertainment": ["Booking.com", "AirBnB", ...],
"Personal Spending": ["Hairsalon", "Shoes", ...],
"Miscellaneous": ["ATM", ...]
}I’ve included some of the keywords I’m using. The food category has the most keywords and in my case contains a list of supermarkets, vending machines, coffee places and restaurants I frequent. You might want to split this category into ‘groceries’ and ‘eating out’, depending on how detailed you want your categories.
The following function uses the dictionary above to classify each transaction. I’m only matching keywords in the columns AdditionalEntryInformation and DetailsRemittanceInformationUnstructured. If you want to match by other columns (such as account number) you can extend this list.
def categorize_transaction(row):
columns = ['AdditionalEntryInformation', 'DetailsRemittanceInformationUnstructured']
for (category, keywords) in categories.items():
for column in columns:
if isinstance(row[column], str) and any([row[column].lower().find(kw.lower()) >= 0 for kw in keywords]):
return category
return NoneA new column will be added to the dataframe with the hopefully correct categorization.
transactions['Category'] = transactions.apply(categorize_transaction, axis=1)Inspecting categories
It requires a bit of trial and error to come up with a good list of keywords. With the following code, we can see which transactions fall into each category. By selecting ‘Uncategorized’ we can see which transactions haven’t been assigned to a category yet.
@interact(iban=widgets.Dropdown(options=statements.IBAN.unique(), description='Account:'), category=widgets.Dropdown(options=list(categories.keys()) + ['Uncategorized'], description='Category:'))
def show_transactions(iban, category):
columns = ['IBAN', 'Amount','CreditDebitIndicator', 'BookingDate', 'ValueDate', 'Issuer', 'AdditionalEntryInformation', 'DetailsAmount', 'DetailsCurrency',
'DetailsCreditorName', 'DetailsCreditorIBAN', 'DetailsRemittanceInformationUnstructured', 'DetailsDebtorName', 'DetailsDebtorIBAN', 'DetailsCreditorCountry']
if category == "Uncategorized":
display(transactions.query('IBAN == @iban & Category.isnull()')[columns])
else:
display(transactions.query('IBAN == @iban & Category == @category')[columns])| IBAN | Amount | CreditDebitIndicator | BookingDate | ValueDate | Issuer | AdditionalEntryInformation | DetailsAmount | DetailsCurrency | DetailsCreditorName | DetailsCreditorIBAN | DetailsRemittanceInformationUnstructured | DetailsDebtorName | DetailsDebtorIBAN | DetailsCreditorCountry |
|---|
In this case all transactions have been categorized.
Plotting the expenses per category
Let’s use a donut chart to visualize how much is spent in each category.
@interact(
iban=widgets.Dropdown(options=statements.IBAN.unique(), description='Account:', layout={'width': '500px'}),
date_range=widgets.SelectionRangeSlider(
options=[(date.strftime(' %b %Y '), date) for date in dates],
index=(0, len(dates)-1),
description='Dates:',
layout={'width': '500px'}
)
)
def plot_expenses_by_category(iban, date_range):
start_date = datetime(date_range[0].year, date_range[0].month, 1)
end_date = date_range[1]
df = transactions.query('IBAN == @iban & ValueDate >= @start_date & ValueDate <= @end_date & Category != "Income"').groupby('Category')['Amount'].sum()
total = df.sum()
ax = df.plot(kind='pie', startangle=90, figsize=(10,10), legend=False, autopct=lambda v: '{:.1f}%\n\u20ac{:.2f}'.format(v, total*v/100))
ax.set_title("Expenses")
ax.axis('off')
ax.add_artist(plt.Circle(xy=(0,0), radius=.75, facecolor='white'))
plt.show()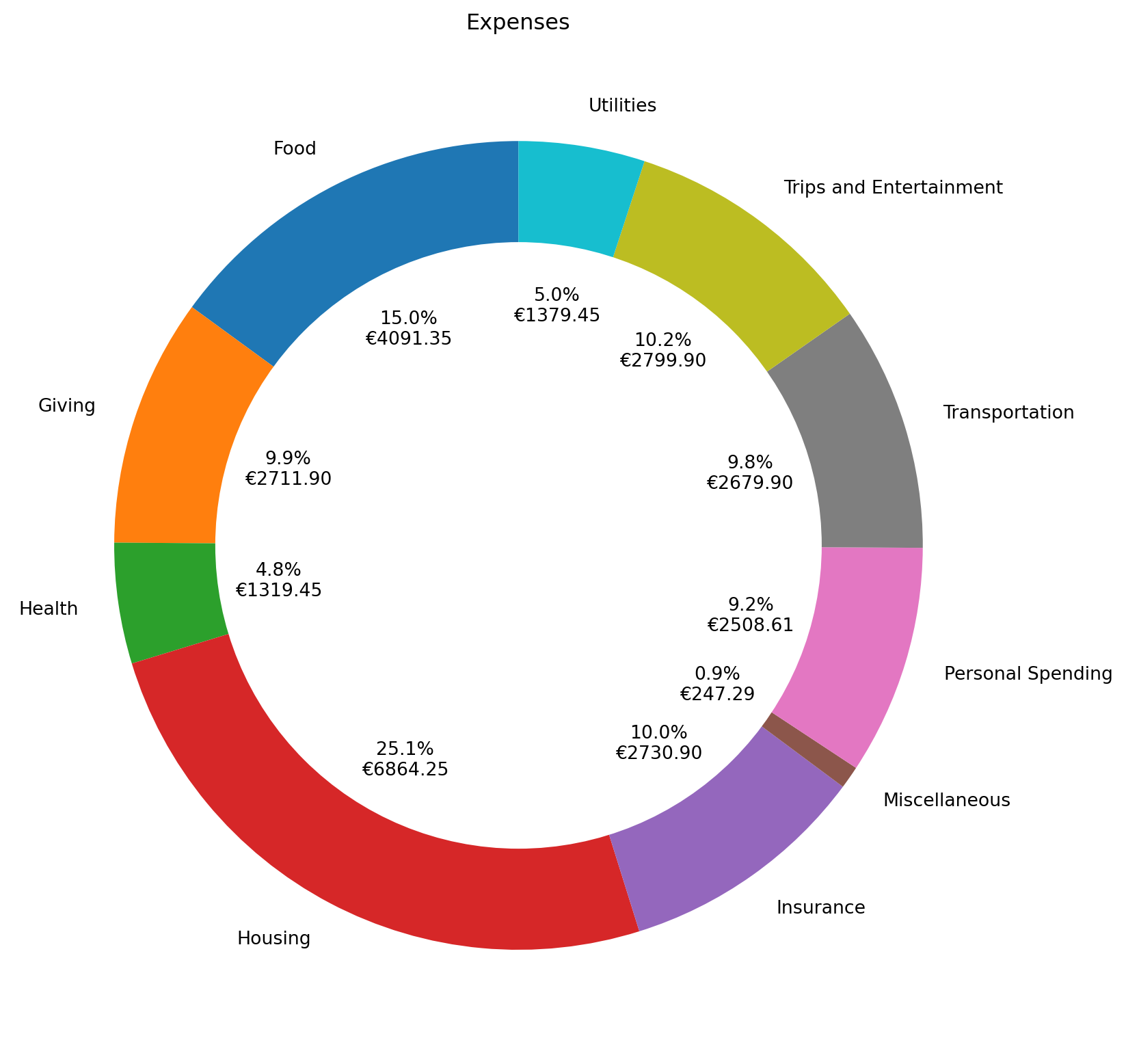
The slider allows for setting a date range. In the example above, I’ve set the date range to the year 2023.
Analyzing your own finances
If you want to try this out with your own data, you can find all the code and the complete Jupyter Notebook in the following GitHub repository:
![]()
Happy tracking!