import json
import numpy as np
import pandas as pd
import ipywidgets as widgets
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import mutual_info_classif
from warnings import simplefilter
from collections import dequeWordle’s addictive nature has caused it to spread like wildfire, captivating players around the world who find themselves entangled in the pursuit of streaks. It has become a quest for daily victories, a battle against time to maintain unbroken chains of triumphant solves. The desire to conquer the next puzzle and extend those streaks has become an obsession that consumes countless hours of human capital.
We’re witnessing a peculiar phenomenon: a society on the brink of crumbling under the weight of unsolved Wordle puzzles. Productivity is plummeting, deadlines are missed, pets and children are neglected while people fret endlessly over deciphering those elusive five-letter words.
In the face of this crisis, I took it upon myself, to save our civilization from its Wordle-induced downfall. The solution was simple: I developed a Wordle solver. Yes, a program designed to expedite the solving process and allow people to return to more important tasks without sacrificing their streaks or sanity.
I am certain that in a few years from now, I’ll be recognized as the hero of productivity, wielding the power of math and Python to restore balance in the world. Please don’t make my statue too big, I’m quite modest.
Read on if you want to learn about the inner workings of my Wordle solver.
How to play Wordle
In case you’re one of the lucky few who hasn’t been caught by the grip of Wordle’s addictive tendrils, let’s go over the rules.
The objective is to guess a five-letter mystery word within six attempts. After each guess, you receive feedback in the form of colored boxes. Green boxes indicate correct letters in the right position, while yellow boxes indicate correct letters in the wrong position. Gray boxes mean the word doesn’t contain this letter.
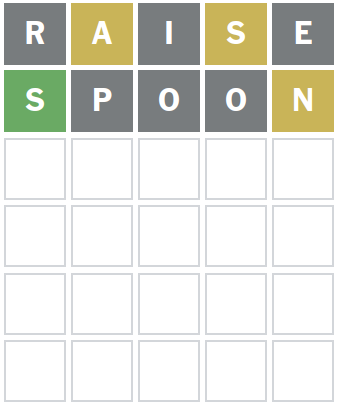
After trying SPOON we know the position of S. We also know that the word must contain an A and a N. The secret word doesn’t contain any of the letters E, R, I, O, or P.
There are four more tries left. Feeling anxious already?
The approach
I started by writing Python code to produce a decision tree to tackle Wordle games. Each node within the tree suggests a word to try. The branches represent the possible color patterns that Wordle provides as feedback. By navigating this tree, players can solve the daily Wordle puzzles.
In this post I’ll first focus on the code for generating the decision tree. Then I’ll presents a user interface built from widgets that enables interactive traversal of this tree.
Importing libraries
We start by importing the necessary libraries. Note how we don’t import any tree models from sklearn as we’ll roll our own.
Getting the list of possible answers
The following list was taken directly from the Wordle JavaScript source code. The source code actually contains two lists. One is the list of possible answers. The second is a list of valid 5-letter words.
We’ll only use the first list. This will still allow the decision tree to solve every possible puzzle reasonably efficiently. Tree induction will be much faster this way.
We might need to update this list in the future if the New York Times decides to update the possible set of answers. You might also want to update this list if you want to create a decision tree for one of the many Wordle clones.
answers_list = ["cigar","rebut","sissy","humph","awake","blush","focal","evade","naval","serve","heath","dwarf","model","karma","stink","grade","quiet","bench","abate","feign","major","death","fresh","crust","stool","colon","abase","marry","react","batty","pride","floss","helix","croak","staff","paper","unfed","whelp","trawl","outdo","adobe","crazy","sower","repay","digit","crate","cluck","spike","mimic","pound","maxim","linen","unmet","flesh","booby","forth","first","stand","belly","ivory","seedy","print","yearn","drain","bribe","stout","panel","crass","flume","offal","agree","error","swirl","argue","bleed","delta","flick","totem","wooer","front","shrub","parry","biome","lapel","start","greet","goner","golem","lusty","loopy","round","audit","lying","gamma","labor","islet","civic","forge","corny","moult","basic","salad","agate","spicy","spray","essay","fjord","spend","kebab","guild","aback","motor","alone","hatch","hyper","thumb","dowry","ought","belch","dutch","pilot","tweed","comet","jaunt","enema","steed","abyss","growl","fling","dozen","boozy","erode","world","gouge","click","briar","great","altar","pulpy","blurt","coast","duchy","groin","fixer","group","rogue","badly","smart","pithy","gaudy","chill","heron","vodka","finer","surer","radio","rouge","perch","retch","wrote","clock","tilde","store","prove","bring","solve","cheat","grime","exult","usher","epoch","triad","break","rhino","viral","conic","masse","sonic","vital","trace","using","peach","champ","baton","brake","pluck","craze","gripe","weary","picky","acute","ferry","aside","tapir","troll","unify","rebus","boost","truss","siege","tiger","banal","slump","crank","gorge","query","drink","favor","abbey","tangy","panic","solar","shire","proxy","point","robot","prick","wince","crimp","knoll","sugar","whack","mount","perky","could","wrung","light","those","moist","shard","pleat","aloft","skill","elder","frame","humor","pause","ulcer","ultra","robin","cynic","aroma","caulk","shake","dodge","swill","tacit","other","thorn","trove","bloke","vivid","spill","chant","choke","rupee","nasty","mourn","ahead","brine","cloth","hoard","sweet","month","lapse","watch","today","focus","smelt","tease","cater","movie","saute","allow","renew","their","slosh","purge","chest","depot","epoxy","nymph","found","shall","harry","stove","lowly","snout","trope","fewer","shawl","natal","comma","foray","scare","stair","black","squad","royal","chunk","mince","shame","cheek","ample","flair","foyer","cargo","oxide","plant","olive","inert","askew","heist","shown","zesty","hasty","trash","fella","larva","forgo","story","hairy","train","homer","badge","midst","canny","fetus","butch","farce","slung","tipsy","metal","yield","delve","being","scour","glass","gamer","scrap","money","hinge","album","vouch","asset","tiara","crept","bayou","atoll","manor","creak","showy","phase","froth","depth","gloom","flood","trait","girth","piety","payer","goose","float","donor","atone","primo","apron","blown","cacao","loser","input","gloat","awful","brink","smite","beady","rusty","retro","droll","gawky","hutch","pinto","gaily","egret","lilac","sever","field","fluff","hydro","flack","agape","voice","stead","stalk","berth","madam","night","bland","liver","wedge","augur","roomy","wacky","flock","angry","bobby","trite","aphid","tryst","midge","power","elope","cinch","motto","stomp","upset","bluff","cramp","quart","coyly","youth","rhyme","buggy","alien","smear","unfit","patty","cling","glean","label","hunky","khaki","poker","gruel","twice","twang","shrug","treat","unlit","waste","merit","woven","octal","needy","clown","widow","irony","ruder","gauze","chief","onset","prize","fungi","charm","gully","inter","whoop","taunt","leery","class","theme","lofty","tibia","booze","alpha","thyme","eclat","doubt","parer","chute","stick","trice","alike","sooth","recap","saint","liege","glory","grate","admit","brisk","soggy","usurp","scald","scorn","leave","twine","sting","bough","marsh","sloth","dandy","vigor","howdy","enjoy","valid","ionic","equal","unset","floor","catch","spade","stein","exist","quirk","denim","grove","spiel","mummy","fault","foggy","flout","carry","sneak","libel","waltz","aptly","piney","inept","aloud","photo","dream","stale","vomit","ombre","fanny","unite","snarl","baker","there","glyph","pooch","hippy","spell","folly","louse","gulch","vault","godly","threw","fleet","grave","inane","shock","crave","spite","valve","skimp","claim","rainy","musty","pique","daddy","quasi","arise","aging","valet","opium","avert","stuck","recut","mulch","genre","plume","rifle","count","incur","total","wrest","mocha","deter","study","lover","safer","rivet","funny","smoke","mound","undue","sedan","pagan","swine","guile","gusty","equip","tough","canoe","chaos","covet","human","udder","lunch","blast","stray","manga","melee","lefty","quick","paste","given","octet","risen","groan","leaky","grind","carve","loose","sadly","spilt","apple","slack","honey","final","sheen","eerie","minty","slick","derby","wharf","spelt","coach","erupt","singe","price","spawn","fairy","jiffy","filmy","stack","chose","sleep","ardor","nanny","niece","woozy","handy","grace","ditto","stank","cream","usual","diode","valor","angle","ninja","muddy","chase","reply","prone","spoil","heart","shade","diner","arson","onion","sleet","dowel","couch","palsy","bowel","smile","evoke","creek","lance","eagle","idiot","siren","built","embed","award","dross","annul","goody","frown","patio","laden","humid","elite","lymph","edify","might","reset","visit","gusto","purse","vapor","crock","write","sunny","loath","chaff","slide","queer","venom","stamp","sorry","still","acorn","aping","pushy","tamer","hater","mania","awoke","brawn","swift","exile","birch","lucky","freer","risky","ghost","plier","lunar","winch","snare","nurse","house","borax","nicer","lurch","exalt","about","savvy","toxin","tunic","pried","inlay","chump","lanky","cress","eater","elude","cycle","kitty","boule","moron","tenet","place","lobby","plush","vigil","index","blink","clung","qualm","croup","clink","juicy","stage","decay","nerve","flier","shaft","crook","clean","china","ridge","vowel","gnome","snuck","icing","spiny","rigor","snail","flown","rabid","prose","thank","poppy","budge","fiber","moldy","dowdy","kneel","track","caddy","quell","dumpy","paler","swore","rebar","scuba","splat","flyer","horny","mason","doing","ozone","amply","molar","ovary","beset","queue","cliff","magic","truce","sport","fritz","edict","twirl","verse","llama","eaten","range","whisk","hovel","rehab","macaw","sigma","spout","verve","sushi","dying","fetid","brain","buddy","thump","scion","candy","chord","basin","march","crowd","arbor","gayly","musky","stain","dally","bless","bravo","stung","title","ruler","kiosk","blond","ennui","layer","fluid","tatty","score","cutie","zebra","barge","matey","bluer","aider","shook","river","privy","betel","frisk","bongo","begun","azure","weave","genie","sound","glove","braid","scope","wryly","rover","assay","ocean","bloom","irate","later","woken","silky","wreck","dwelt","slate","smack","solid","amaze","hazel","wrist","jolly","globe","flint","rouse","civil","vista","relax","cover","alive","beech","jetty","bliss","vocal","often","dolly","eight","joker","since","event","ensue","shunt","diver","poser","worst","sweep","alley","creed","anime","leafy","bosom","dunce","stare","pudgy","waive","choir","stood","spoke","outgo","delay","bilge","ideal","clasp","seize","hotly","laugh","sieve","block","meant","grape","noose","hardy","shied","drawl","daisy","putty","strut","burnt","tulip","crick","idyll","vixen","furor","geeky","cough","naive","shoal","stork","bathe","aunty","check","prime","brass","outer","furry","razor","elect","evict","imply","demur","quota","haven","cavil","swear","crump","dough","gavel","wagon","salon","nudge","harem","pitch","sworn","pupil","excel","stony","cabin","unzip","queen","trout","polyp","earth","storm","until","taper","enter","child","adopt","minor","fatty","husky","brave","filet","slime","glint","tread","steal","regal","guest","every","murky","share","spore","hoist","buxom","inner","otter","dimly","level","sumac","donut","stilt","arena","sheet","scrub","fancy","slimy","pearl","silly","porch","dingo","sepia","amble","shady","bread","friar","reign","dairy","quill","cross","brood","tuber","shear","posit","blank","villa","shank","piggy","freak","which","among","fecal","shell","would","algae","large","rabbi","agony","amuse","bushy","copse","swoon","knife","pouch","ascot","plane","crown","urban","snide","relay","abide","viola","rajah","straw","dilly","crash","amass","third","trick","tutor","woody","blurb","grief","disco","where","sassy","beach","sauna","comic","clued","creep","caste","graze","snuff","frock","gonad","drunk","prong","lurid","steel","halve","buyer","vinyl","utile","smell","adage","worry","tasty","local","trade","finch","ashen","modal","gaunt","clove","enact","adorn","roast","speck","sheik","missy","grunt","snoop","party","touch","mafia","emcee","array","south","vapid","jelly","skulk","angst","tubal","lower","crest","sweat","cyber","adore","tardy","swami","notch","groom","roach","hitch","young","align","ready","frond","strap","puree","realm","venue","swarm","offer","seven","dryer","diary","dryly","drank","acrid","heady","theta","junto","pixie","quoth","bonus","shalt","penne","amend","datum","build","piano","shelf","lodge","suing","rearm","coral","ramen","worth","psalm","infer","overt","mayor","ovoid","glide","usage","poise","randy","chuck","prank","fishy","tooth","ether","drove","idler","swath","stint","while","begat","apply","slang","tarot","radar","credo","aware","canon","shift","timer","bylaw","serum","three","steak","iliac","shirk","blunt","puppy","penal","joist","bunny","shape","beget","wheel","adept","stunt","stole","topaz","chore","fluke","afoot","bloat","bully","dense","caper","sneer","boxer","jumbo","lunge","space","avail","short","slurp","loyal","flirt","pizza","conch","tempo","droop","plate","bible","plunk","afoul","savoy","steep","agile","stake","dwell","knave","beard","arose","motif","smash","broil","glare","shove","baggy","mammy","swamp","along","rugby","wager","quack","squat","snaky","debit","mange","skate","ninth","joust","tramp","spurn","medal","micro","rebel","flank","learn","nadir","maple","comfy","remit","gruff","ester","least","mogul","fetch","cause","oaken","aglow","meaty","gaffe","shyly","racer","prowl","thief","stern","poesy","rocky","tweet","waist","spire","grope","havoc","patsy","truly","forty","deity","uncle","swish","giver","preen","bevel","lemur","draft","slope","annoy","lingo","bleak","ditty","curly","cedar","dirge","grown","horde","drool","shuck","crypt","cumin","stock","gravy","locus","wider","breed","quite","chafe","cache","blimp","deign","fiend","logic","cheap","elide","rigid","false","renal","pence","rowdy","shoot","blaze","envoy","posse","brief","never","abort","mouse","mucky","sulky","fiery","media","trunk","yeast","clear","skunk","scalp","bitty","cider","koala","duvet","segue","creme","super","grill","after","owner","ember","reach","nobly","empty","speed","gipsy","recur","smock","dread","merge","burst","kappa","amity","shaky","hover","carol","snort","synod","faint","haunt","flour","chair","detox","shrew","tense","plied","quark","burly","novel","waxen","stoic","jerky","blitz","beefy","lyric","hussy","towel","quilt","below","bingo","wispy","brash","scone","toast","easel","saucy","value","spice","honor","route","sharp","bawdy","radii","skull","phony","issue","lager","swell","urine","gassy","trial","flora","upper","latch","wight","brick","retry","holly","decal","grass","shack","dogma","mover","defer","sober","optic","crier","vying","nomad","flute","hippo","shark","drier","obese","bugle","tawny","chalk","feast","ruddy","pedal","scarf","cruel","bleat","tidal","slush","semen","windy","dusty","sally","igloo","nerdy","jewel","shone","whale","hymen","abuse","fugue","elbow","crumb","pansy","welsh","syrup","terse","suave","gamut","swung","drake","freed","afire","shirt","grout","oddly","tithe","plaid","dummy","broom","blind","torch","enemy","again","tying","pesky","alter","gazer","noble","ethos","bride","extol","decor","hobby","beast","idiom","utter","these","sixth","alarm","erase","elegy","spunk","piper","scaly","scold","hefty","chick","sooty","canal","whiny","slash","quake","joint","swept","prude","heavy","wield","femme","lasso","maize","shale","screw","spree","smoky","whiff","scent","glade","spent","prism","stoke","riper","orbit","cocoa","guilt","humus","shush","table","smirk","wrong","noisy","alert","shiny","elate","resin","whole","hunch","pixel","polar","hotel","sword","cleat","mango","rumba","puffy","filly","billy","leash","clout","dance","ovate","facet","chili","paint","liner","curio","salty","audio","snake","fable","cloak","navel","spurt","pesto","balmy","flash","unwed","early","churn","weedy","stump","lease","witty","wimpy","spoof","saner","blend","salsa","thick","warty","manic","blare","squib","spoon","probe","crepe","knack","force","debut","order","haste","teeth","agent","widen","icily","slice","ingot","clash","juror","blood","abode","throw","unity","pivot","slept","troop","spare","sewer","parse","morph","cacti","tacky","spool","demon","moody","annex","begin","fuzzy","patch","water","lumpy","admin","omega","limit","tabby","macho","aisle","skiff","basis","plank","verge","botch","crawl","lousy","slain","cubic","raise","wrack","guide","foist","cameo","under","actor","revue","fraud","harpy","scoop","climb","refer","olden","clerk","debar","tally","ethic","cairn","tulle","ghoul","hilly","crude","apart","scale","older","plain","sperm","briny","abbot","rerun","quest","crisp","bound","befit","drawn","suite","itchy","cheer","bagel","guess","broad","axiom","chard","caput","leant","harsh","curse","proud","swing","opine","taste","lupus","gumbo","miner","green","chasm","lipid","topic","armor","brush","crane","mural","abled","habit","bossy","maker","dusky","dizzy","lithe","brook","jazzy","fifty","sense","giant","surly","legal","fatal","flunk","began","prune","small","slant","scoff","torus","ninny","covey","viper","taken","moral","vogue","owing","token","entry","booth","voter","chide","elfin","ebony","neigh","minim","melon","kneed","decoy","voila","ankle","arrow","mushy","tribe","cease","eager","birth","graph","odder","terra","weird","tried","clack","color","rough","weigh","uncut","ladle","strip","craft","minus","dicey","titan","lucid","vicar","dress","ditch","gypsy","pasta","taffy","flame","swoop","aloof","sight","broke","teary","chart","sixty","wordy","sheer","leper","nosey","bulge","savor","clamp","funky","foamy","toxic","brand","plumb","dingy","butte","drill","tripe","bicep","tenor","krill","worse","drama","hyena","think","ratio","cobra","basil","scrum","bused","phone","court","camel","proof","heard","angel","petal","pouty","throb","maybe","fetal","sprig","spine","shout","cadet","macro","dodgy","satyr","rarer","binge","trend","nutty","leapt","amiss","split","myrrh","width","sonar","tower","baron","fever","waver","spark","belie","sloop","expel","smote","baler","above","north","wafer","scant","frill","awash","snack","scowl","frail","drift","limbo","fence","motel","ounce","wreak","revel","talon","prior","knelt","cello","flake","debug","anode","crime","salve","scout","imbue","pinky","stave","vague","chock","fight","video","stone","teach","cleft","frost","prawn","booty","twist","apnea","stiff","plaza","ledge","tweak","board","grant","medic","bacon","cable","brawl","slunk","raspy","forum","drone","women","mucus","boast","toddy","coven","tumor","truer","wrath","stall","steam","axial","purer","daily","trail","niche","mealy","juice","nylon","plump","merry","flail","papal","wheat","berry","cower","erect","brute","leggy","snipe","sinew","skier","penny","jumpy","rally","umbra","scary","modem","gross","avian","greed","satin","tonic","parka","sniff","livid","stark","trump","giddy","reuse","taboo","avoid","quote","devil","liken","gloss","gayer","beret","noise","gland","dealt","sling","rumor","opera","thigh","tonga","flare","wound","white","bulky","etude","horse","circa","paddy","inbox","fizzy","grain","exert","surge","gleam","belle","salvo","crush","fruit","sappy","taker","tract","ovine","spiky","frank","reedy","filth","spasm","heave","mambo","right","clank","trust","lumen","borne","spook","sauce","amber","lathe","carat","corer","dirty","slyly","affix","alloy","taint","sheep","kinky","wooly","mauve","flung","yacht","fried","quail","brunt","grimy","curvy","cagey","rinse","deuce","state","grasp","milky","bison","graft","sandy","baste","flask","hedge","girly","swash","boney","coupe","endow","abhor","welch","blade","tight","geese","miser","mirth","cloud","cabal","leech","close","tenth","pecan","droit","grail","clone","guise","ralph","tango","biddy","smith","mower","payee","serif","drape","fifth","spank","glaze","allot","truck","kayak","virus","testy","tepee","fully","zonal","metro","curry","grand","banjo","axion","bezel","occur","chain","nasal","gooey","filer","brace","allay","pubic","raven","plead","gnash","flaky","munch","dully","eking","thing","slink","hurry","theft","shorn","pygmy","ranch","wring","lemon","shore","mamma","froze","newer","style","moose","antic","drown","vegan","chess","guppy","union","lever","lorry","image","cabby","druid","exact","truth","dopey","spear","cried","chime","crony","stunk","timid","batch","gauge","rotor","crack","curve","latte","witch","bunch","repel","anvil","soapy","meter","broth","madly","dried","scene","known","magma","roost","woman","thong","punch","pasty","downy","knead","whirl","rapid","clang","anger","drive","goofy","email","music","stuff","bleep","rider","mecca","folio","setup","verso","quash","fauna","gummy","happy","newly","fussy","relic","guava","ratty","fudge","femur","chirp","forte","alibi","whine","petty","golly","plait","fleck","felon","gourd","brown","thrum","ficus","stash","decry","wiser","junta","visor","daunt","scree","impel","await","press","whose","turbo","stoop","speak","mangy","eying","inlet","crone","pulse","mossy","staid","hence","pinch","teddy","sully","snore","ripen","snowy","attic","going","leach","mouth","hound","clump","tonal","bigot","peril","piece","blame","haute","spied","undid","intro","basal","shine","gecko","rodeo","guard","steer","loamy","scamp","scram","manly","hello","vaunt","organ","feral","knock","extra","condo","adapt","willy","polka","rayon","skirt","faith","torso","match","mercy","tepid","sleek","riser","twixt","peace","flush","catty","login","eject","roger","rival","untie","refit","aorta","adult","judge","rower","artsy","rural","shave"]Next we’ll turn this list into a Series object. We’ll also sort the answers.
answers = pd.Series(answers_list).sort_values(ignore_index=True)Wordle’s clues algorithm
After each guess Wordle provides you with clues as to how close your guess was. Instead of colors we’ll use the following encoding:
- F (False), the letter does not appear in the word in any spot;
- P (Position), the letter appears in the word but is in the wrong spot;
- T (True), the letter is in the word and in the correct spot.
The match function generates the clues for a guess and an answer.
def match(guess, answer):
result = ['F'] * 5
chars = list(answer)
# Mark correct letter and position as T
for i in range(5):
if guess[i] == answer[i]:
result[i] = 'T'
chars[i] = '_'
# Mark correct letter, wrong position as P
for i in range(5):
for j in range(5):
if guess[i] == chars[j] and result[i] == 'F':
result[i] = 'P'
chars[j] = '_'
# All other positions are marked as F by default
return ''.join(result)Filling the DataFrame
Using the wordlist and the match function we can create the DataFrame we’ll use to build the decision tree.
# Add column with possible answers
df = answers.to_frame(name="answer")# Suppress PerformanceWarning
simplefilter(action="ignore", category=pd.errors.PerformanceWarning)
# Add columns for answers
for index, value in answers.items():
df[value] = df["answer"].map(lambda v: match(value, v))Let’s print the first ten rows to see how things turned out.
df.head(10)| answer | aback | abase | abate | abbey | abbot | abhor | abide | abled | abode | ... | wryly | yacht | yearn | yeast | yield | young | youth | zebra | zesty | zonal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | aback | TTTTT | TTTFF | TTTFF | TTFFF | TTFFF | TTFFF | TTFFF | TTFFF | TTFFF | ... | FFFFF | FPPFF | FFTFF | FFTFF | FFFFF | FFFFF | FFFFF | FFPFP | FFFFF | FFFPF |
| 1 | abase | TTTFF | TTTTT | TTTFT | TTFPF | TTFFF | TTFFF | TTFFT | TTFPF | TTFFT | ... | FFFFF | FPFFF | FPTFF | FPTTF | FFPFF | FFFFF | FFFFF | FPPFP | FPPFF | FFFPF |
| 2 | abate | TTTFF | TTTFT | TTTTT | TTFPF | TTFFP | TTFFF | TTFFT | TTFPF | TTFFT | ... | FFFFF | FPFFP | FPTFF | FPTFP | FFPFF | FFFFF | FFFTF | FPPFP | FPFTF | FFFPF |
| 3 | abbey | TTFFF | TTFFP | TTFFP | TTTTT | TTTFF | TTFFF | TTFFP | TTFTF | TTFFP | ... | FFFFT | PPFFF | PPPFF | PPPFF | PFPFF | PFFFF | PFFFF | FPTFP | FPFFT | FFFPF |
| 4 | abbot | TTFFF | TTFFF | TTFPF | TTTFF | TTTTT | TTFTF | TTFFF | TTFFF | TTPFF | ... | FFFFF | FPFFT | FFPFF | FFPFT | FFFFF | FPFFF | FPFPF | FFTFP | FFFPF | FPFPF |
| 5 | abhor | TTFFF | TTFFF | TTFFF | TTFFF | TTFTF | TTTTT | TTFFF | TTFFF | TTPFF | ... | FPFFF | FPFPF | FFPPF | FFPFF | FFFFF | FPFFF | FPFFP | FFPPP | FFFFF | FPFPF |
| 6 | abide | TTFFF | TTFFT | TTFFT | TTFPF | TTFFF | TTFFF | TTTTT | TTFPP | TTFTT | ... | FFFFF | FPFFF | FPPFF | FPPFF | FPPFP | FFFFF | FFFFF | FPPFP | FPFFF | FFFPF |
| 7 | abled | TTFFF | TTFFP | TTFFP | TTFTF | TTFFF | TTFFF | TTFPP | TTTTT | TTFPP | ... | FFFPF | FPFFF | FPPFF | FPPFF | FFPPT | FFFFF | FFFFF | FPPFP | FPFFF | FFFPP |
| 8 | abode | TTFFF | TTFFT | TTFFT | TTFPF | TTFPF | TTFPF | TTFTT | TTFPP | TTTTT | ... | FFFFF | FPFFF | FPPFF | FPPFF | FFPFP | FPFFF | FPFFF | FPPFP | FPFFF | FPFPF |
| 9 | abort | TTFFF | TTFFF | TTFPF | TTFFF | TTFPT | TTFPP | TTFFF | TTFFF | TTTFF | ... | FPFFF | FPFFT | FFPTF | FFPFT | FFFFF | FPFFF | FPFPF | FFPTP | FFFPF | FPFPF |
10 rows × 2310 columns
Preprocessing
We’ll separate the DataFrame into features and the target variable. Then we’ll use sklearn’s LabelEncoder to convert the features into numeric values. We’ll use the same encoding for all columns. We do this because in our tree induction algorithm below we use sklearn’s mutual_info_classif function that expects features to be numeric.
X = df.drop(columns="answer")
y = df["answer"]Let’s prepare the label encoder.
le = LabelEncoder()
le.fit(X.stack().unique())LabelEncoder()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LabelEncoder()
Now we can convert all columns.
X = X.apply(le.transform)Again, let’s print the first few rows to check if the encoding went alright.
X.head()| aback | abase | abate | abbey | abbot | abhor | abide | abled | abode | abort | ... | wryly | yacht | yearn | yeast | yield | young | youth | zebra | zesty | zonal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 237 | 231 | 231 | 214 | 214 | 214 | 214 | 214 | 214 | 214 | ... | 0 | 36 | 18 | 18 | 0 | 0 | 0 | 10 | 0 | 3 |
| 1 | 231 | 237 | 233 | 217 | 214 | 214 | 216 | 217 | 216 | 214 | ... | 0 | 27 | 45 | 51 | 9 | 0 | 0 | 37 | 36 | 3 |
| 2 | 231 | 233 | 237 | 217 | 215 | 214 | 216 | 217 | 216 | 215 | ... | 0 | 28 | 45 | 46 | 9 | 0 | 6 | 37 | 33 | 3 |
| 3 | 214 | 215 | 215 | 237 | 231 | 214 | 215 | 220 | 215 | 214 | ... | 2 | 108 | 117 | 117 | 90 | 81 | 81 | 46 | 29 | 3 |
| 4 | 214 | 214 | 217 | 231 | 237 | 220 | 214 | 214 | 223 | 225 | ... | 0 | 29 | 9 | 11 | 0 | 27 | 30 | 19 | 3 | 30 |
5 rows × 2309 columns
We can see that the patterns have been replaced by numbers. Every number is an index of a value in the le.classes_ array. For demonstration purposes, let’s look at the first 10 items of this array.
le.classes_[:10]array(['FFFFF', 'FFFFP', 'FFFFT', 'FFFPF', 'FFFPP', 'FFFPT', 'FFFTF',
'FFFTP', 'FFFTT', 'FFPFF'], dtype=object)Tree induction
Now we’re ready to generate our tree.
Several tree induction algorithms exist. They generally work top down and use some metric to determine what feature to split by at each node. The sklearn library provides CART (Classification And Regression Trees) that by default use the Gini impurity as a metric. Nodes in CART, however, only support binary splits which would make our decision tree unnecessarily deep and large. An alternative candidate algorithm could be ID3 or ID4.5. These algorithms use a concept known as information gain (the reduction in entropy after splitting by a variable) to determine what feature to split by, and they support non-binary nodes. A few Python libraries exist that implement ID3/ID4.5. We could use one of those. However, we require a bit more control over how we select the best feature, which is why we roll our own tree induction algorithm.
To determine what feature (word) to split by in each node, we use a metric called mutual information which is the expected value of the information gain. This metric is commonly used for feature selection and is already provided by the sklearn library as mutual_info_classif. At each node multiple words might be equally good candidates; therefor, in addition to mutual information, we will also consider whether a feature could actually be the correct answer which will generally lead to slightly more optimal trees.
The approach I describe here won’t guarantee an optimal tree. We’re using a greedy strategy to select the most promising features. Selecting less promising features earlier on might yield more optimal splits at a later stage; however, tree induction would take much longer. We’ll still end up with an efficient tree for solving the daily Wordle, there’s just no guarantee it will be the optimal one. Realise that this is true for tree induction algorithms like CART/ID3/ID4.5 as well. Tree induction algorithms simply make locally optimal choices at each split based on the available data, and these choices may not lead to the overall best tree structure.
class WordleDecisionTree:
def fit(self, input, output, labels):
data = input.copy()
data[output.name] = output
self.labels = labels
self.tree = self.decision_tree(data, data, input.columns, output.name)
def decision_tree(self, data, orginal_data, feature_attribute_names, target_attribute_name):
unique_classes = np.unique(data[target_attribute_name])
if len(unique_classes) <= 1:
return unique_classes[0]
else:
# determine best feature using mutual information
stats = dict(zip(feature_attribute_names, mutual_info_classif(
data[feature_attribute_names],
data[target_attribute_name],
discrete_features=True)
))
best_feature = max(stats, key=lambda key: stats[key])
# create tree structure, empty at first
tree = {best_feature: {}}
# remove best feature from available features, it will become the parent node
feature_attribute_names = [i for i in feature_attribute_names if i != best_feature]
# create nodes under parent node
parent_attribute_values = np.unique(data[best_feature])
for value in parent_attribute_values:
sub_data = data.where(data[best_feature] == value).dropna()
remaining_features = np.unique(sub_data[target_attribute_name])
if len(remaining_features) <= 2:
subtree = self.decision_tree(sub_data, orginal_data, remaining_features, target_attribute_name)
else:
subtree = self.decision_tree(sub_data, orginal_data, feature_attribute_names, target_attribute_name)
# add subtree to original tree
if self.labels[int(value)] != "TTTTT":
tree[best_feature][self.labels[int(value)]] = subtree
return treeWe’ll instantiate this class and generate the tree. This took about 12 minutes on my machine.
model = WordleDecisionTree()
model.fit(X, y, le.classes_)The tree is stored as a nested Python dictionary. Let’s convert it to a JSON string and print the first fifteen lines.
print('\n'.join(json.dumps(model.tree, indent=4).split('\n')[:15])){
"raise": {
"FFFFF": {
"mulch": {
"FFFFF": {
"goody": {
"FFTFF": "known",
"FTFFT": {
"bobby": {
"FTFFT": "poppy"
}
},
"FTFPT": "downy",
"FTFTT": {
"dowdy": {The root node of this tree shows the best word to start with. Again, remember that we are only considering words that could actually be a valid answer. We can’t make any claims about this word being the best word to start with. What we can claim however is that on some day we will guess the correct answer on a first try.
print(next(iter(model.tree)))raiseWe can determine the max depth of the decision tree.
def depth(d):
queue = deque([(id(d), d, 1)])
memo = set()
while queue:
id_, o, level = queue.popleft()
if id_ in memo:
continue
memo.add(id_)
if isinstance(o, dict):
queue += ((id(v), v, level + 1) for v in o.values())
return leveldepth(model.tree)11Every level in this nested dictionary is either a guess or a response. So a depth of 11 shows we can always guess the correct answer in 6 tries or less. I imagine you letting out a huge sigh of relief now.
Saving the decision tree
We’ll save the decision tree as a JSON file so we don’t have to rerun the previous steps.
with open('wordle.json', 'w') as fp:
json.dump(model.tree, fp)Loading the decision tree
Whenever we want to use the decision tree, we can just load it. Here we load it into the variable tree.
with open('wordle.json', 'r') as fp:
tree = json.load(fp)Using the decision tree
The first word to try, as we’ve already seen is:
print(next(iter(tree)))raiseAfter we try raise we might get feedback such as ‘FPFFP’. We can use this to get the next guess:
print(next(iter(tree['raise']['FPFFP'])))cleatSuppose that after trying this word we get back ‘FTTTT’. We can just expand the chain of keys to find out what the next guess should be.
print(next(iter(tree['raise']['FPFFP']['cleat']['FTTTT'])))bleatAnd so on until the word has been guessed.
Creating the user interface
Traversing the decision tree like this is a bit cumbersome. Let’s build the GUI using Jupyter widgets to ease navigating the tree. We’ll display a grid which shows the next guess. Every element in this grid is a button widget. We change the caption on these buttons to display the next word to try. By clicking these buttons you can change their color to enter the clues Wordle provides as feedback.
We let traverse_tree be equal to the root node of the decision tree. We start at the top row of the grid.
traverse_tree = tree
active_row = 0We update the color of the button every time it is clicked. On every update we traverse the tree and find the next guess.
def on_btn_click(b, row, col):
global traverse_tree
global active_row
for r in range(6):
enable_row(r, r==row)
if active_row < row:
traverse_tree = traverse_tree[get_word(row - 1)][get_pattern(row - 1)]
active_row = row
if b.style.button_color == '#FFFFFF':
b.style.button_color = '#C9B458'
elif b.style.button_color == '#C9B458':
b.style.button_color = '#787C7E'
elif b.style.button_color == '#787C7E':
b.style.button_color = '#6AAA64'
elif b.style.button_color == '#6AAA64':
b.style.button_color = '#C9B458'
if row < 6:
pattern = get_pattern(row)
if pattern:
set_word(row + 1, get_next_word(row).upper())
else:
set_word(row + 1, " ")
enable_row(row + 1, get_word(row + 1).strip())The following function finds the next guess in the tree.
def get_next_word(row):
try:
if isinstance(traverse_tree[get_word(row)][get_pattern(row)],str):
return traverse_tree[get_word(row)][get_pattern(row)]
return next(iter(traverse_tree[get_word(row)][get_pattern(row)]))
except:
return " "
return " "We want to call on_btn_click() for every button in the interface. A function that handles a click on a button only takes one argument, the button that is clicked. However, the on_btn_click() takes three arguments: the button, the row and the column. To bind the on_btn_click() to each button we use some glue code. The following function returns a handler for every button’s click. Each handler encapsulates the row and column in the grid and forwards the call to the on_btn_click().
def create_on_btn_click_fun(row, col):
def _on_btn_click(b):
on_btn_click(b, row, col)
return _on_btn_clickWe need a function the display the next guess in a row in the grid.
def set_word(row, word):
for c in range(5):
vbox.children[row].children[c].description = word[c]We want the player to only press buttons in the currently active row. For this we create a function that can enable or disable a row.
def enable_row(row,b):
for c in range(5):
vbox.children[row].children[c].disabled = not bOnce the user has completely set the pattern in a row we want to return this pattern. The following function takes care of this. If not all colors have been set yet, it will return None.
def get_pattern(row):
pattern = []
for c in range(5):
if vbox.children[row].children[c].style.button_color == '#FFFFFF':
return None
elif vbox.children[row].children[c].style.button_color == '#C9B458':
pattern.append('P')
elif vbox.children[row].children[c].style.button_color == '#787C7E':
pattern.append('F')
elif vbox.children[row].children[c].style.button_color == '#6AAA64':
pattern.append('T')
return ''.join(pattern)We also write a function that returns the word in a row.
def get_word(row):
letters = []
for c in range(5):
letters.append(vbox.children[row].children[c].description)
return ''.join(letters).lower()We need to be able to clear the grid and set it up to solve another puzzle.
def on_reset_button_click(b):
global traverse_tree
global active_row
for r in range(6):
enable_row(r, r==0)
for c in range(5):
b = vbox.children[r].children[c]
b.style.button_color = '#FFFFFF'
b.description = ' '
traverse_tree = tree
active_row = 0
set_word(0, next(iter(traverse_tree)).upper())Now, let’s display the actual grid and a reset button.
vbox_items = []
for r in range(6):
hbox_items = []
for c in range(5):
button = widgets.Button(description=' ', style=dict(button_color='#FFFFFF', font_weight='bold'), layout=widgets.Layout(width='32px', height='32px', border='solid 1px'))
button.on_click(create_on_btn_click_fun(r,c))
hbox_items.append(button)
vbox_items.append(widgets.HBox(hbox_items))
vbox = widgets.VBox(vbox_items)
reset_button = widgets.Button(description="Reset")
reset_button.on_click(on_reset_button_click)
display(vbox, reset_button)
on_reset_button_click(reset_button)To use this GUI, you simply enter the suggested word into Wordle. By clicking the letters you change the colors and get the next guess.
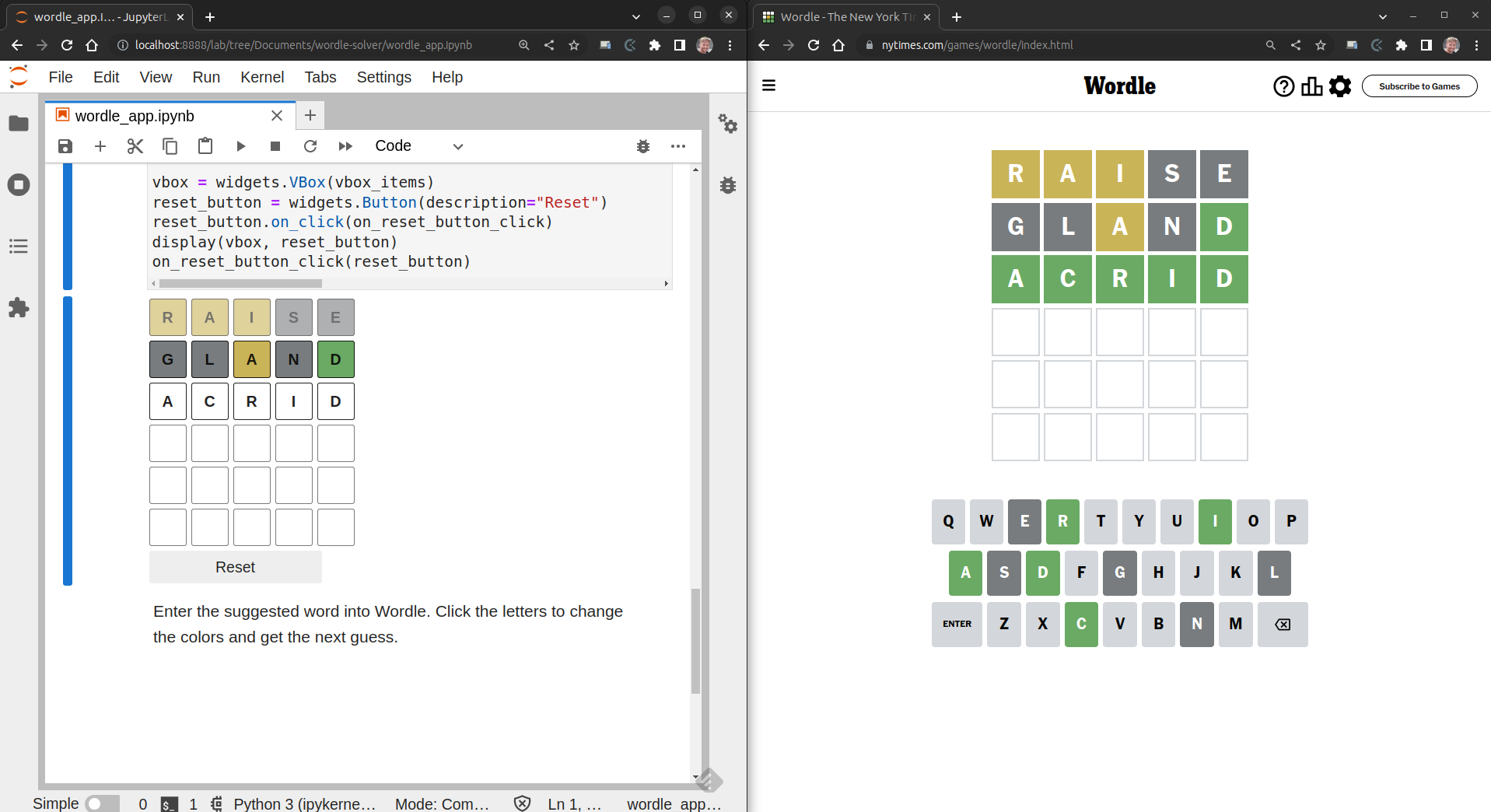
Taking back control of your life
Use one of the following links to play with an interactive version:
![]()

![]()
![]()
The binder link points to a minimal Voila web app version that just loads the decision tree from file and displays the user interface. The other links include the actual tree induction algorithm.
Now you no longer need to worry about keeping your streak going. Please go back to doing something useful!